Dealing with Imbalanced Data: Should You Use SMOTE or Conditional GAN for Your Classifier?

When given a task of building a machine learning model for classification issue, data scientists will check the target variable distribution. If there is an imbalanced distribution, such as 1% as fraudulent and 99% as non-fraudulent for an insurance claim dataset, they will consider using gradient based technique for building the machine learning model such as gradient boosting or XGBoost. However, these models can hardly have a decent performance when the imbalance distribution is as extreme as 1% to 99% . When this happens, data scientists will generally turn to synthetic data before training the machine learning model. In this blog, two popular methods for synthetic data generations (mainly tabular data) including SMOTE and Conditional Tabular Generative Adversarial Networks (CTGAN) will be introduced and compared.
SMOTE
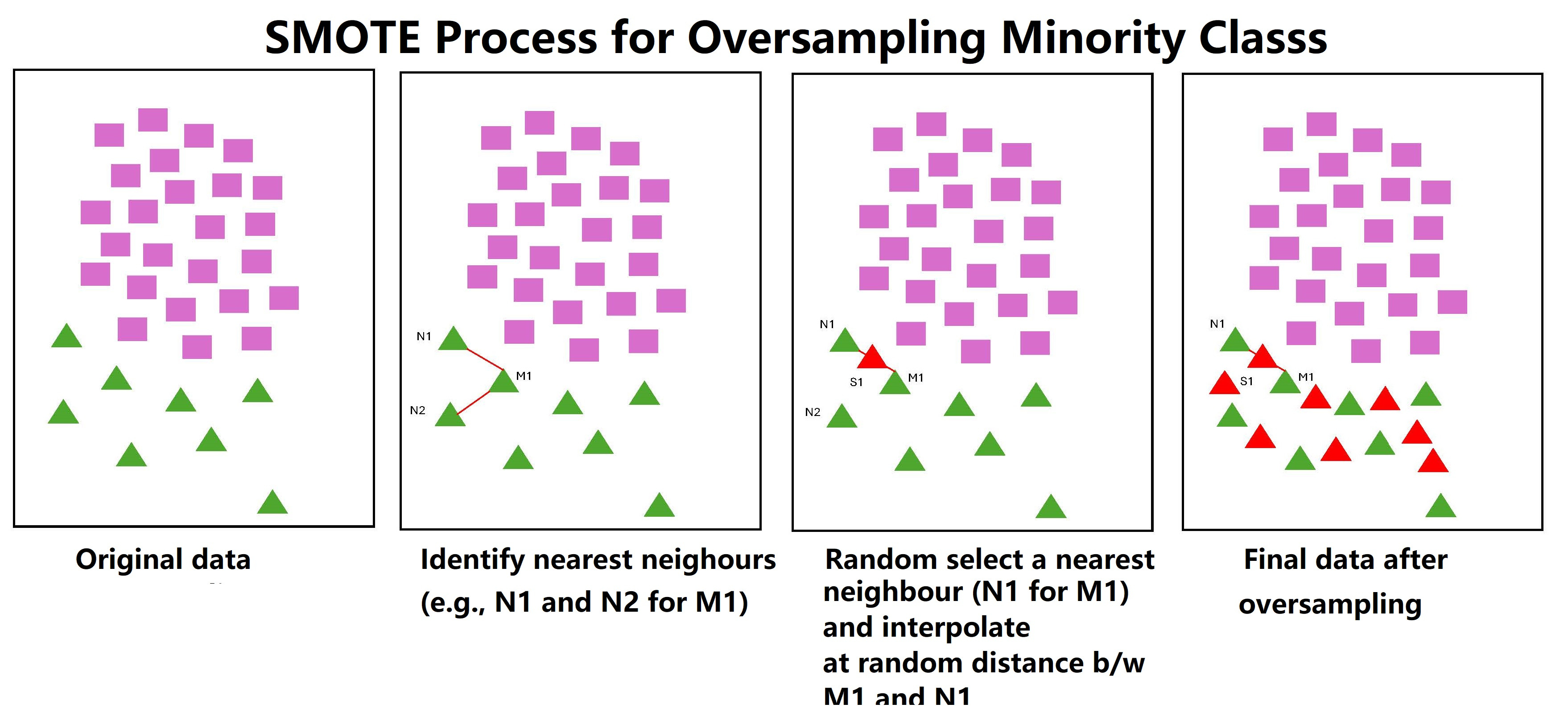
One commonly used method is called SMOTE (Synthetic Minority Over-sampling Technique). As indicate in its name, SMOTE will oversample the minority class so that data scientists can have an accepted ratio between minority and majority class, such as 20% to 80%. Taking a further analysis of how SMOTE works can help to understand the limitations of this method. Figure 1 shows the process of how SMOTE generates the synthetic data to oversample the minority class.